
Die Anfänge
Im April 1999 wollten zwei Schüler, Thomas Wagner und Aaron Praktiknjo, eine Homepage ins Internet stellen, weil das gerade "in" war. Es sollte eine Seite sein, die der Allgemeinheit etwas nützt. Und weil gerade eine Cover-Version im Radio lief – was in den 90er Jahren nicht ungewöhlich war, weil zu der Zeit viele Cover-Versionen in den Charts waren –, war die Idee für das Thema der Homepage geboren: Cover-Versionen in den Charts.Durch Brainstorming und zusätzlich eine Durchforstung der aktuellen Top 100 kamen rund 50 Cover-Versionen zusammen, die jeweils mit Interpret und Titel den (vermuteten) Originalen tabellarisch gegenübergestellt wurden. Alles Weitere setzte Thomas Wagner um. Am 14. April 1999 erstellte er dann abschließend ein Banner mit dem Schriftzug des Namens der Seite auf kunterbuntem Hintergrund und lud das Ganze auf den Webserver seines Internetzugangsproviders hoch. Weil sich der Pfad http://www1.inetmail.de/w9000185/cover/ nur schwer merken ließ, sollte eine kurze und leichter zu merkende Subdomain bei einem Anbieter her, bei dem man kostenlos zu dem komplizierteren Pfad umleiten lassen konnte. So wurde die Subdomain cover.here.de angelegt. Natürlich wurde diese Adresse auch bei zwei Dutzend Suchmaschinen angemeldet.
Die Besucher wurden auf der Website dazu aufgerufen, per E-Mail Ergänzungen zu melden. Und es dauerte nicht lange, bis nicht nur die Seite gefunden wurde, sondern nach einigen Tagen auch schon die ersten Leute Einsendungen machten, die Thomas Wagner in regelmäßigen Abständen eingepflegte.
Schnelles Wachstum
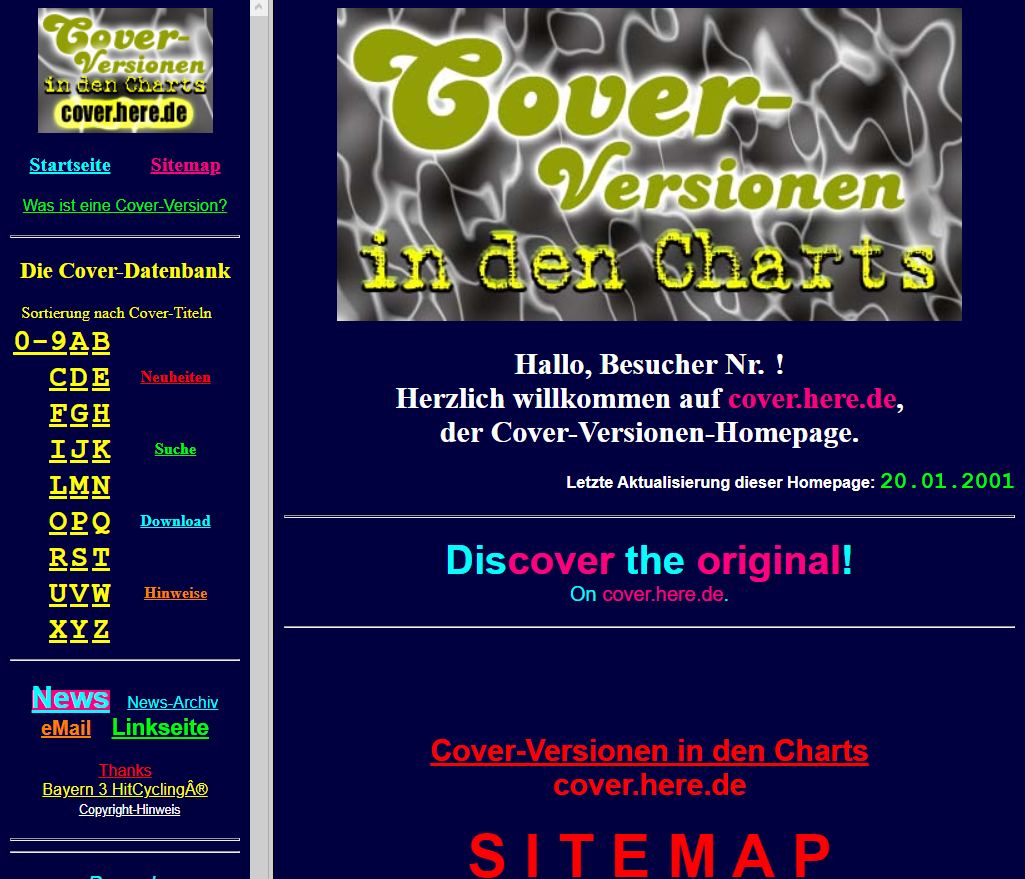
Aus alten Backups wissen wir heute, dass wir am 30. August 1999, also nur viereinhalb Monate später, schon 1.346 Einträge zusammen hatten. Während am ersten Tag noch alles unsortiert auf einer einzigen HTML-Seite mit olivgrünem Hintergrund gestanden hatte, wäre das angesichts der damaligen langsamen Internetleitungen nicht mehr sinnvoll gewesen, weil die Ladezeiten zu lang geworden wären. (Mit dem sog. 56k-Modem kam man faktisch auf rund 40 kbit/s, ähnlich wie wenn heute das mobile Internet gedrosselt wurde.) So wurde die Cover-Versionen-Liste in seinerzeit noch 5 Listen aufgeteilt, die interessanterweise nach Cover-Interpreten, nicht etwa nach Songs sortiert war. Eine echte Datenbank war das also nicht, sondern einfach eine Auflistung in Tabellen auf HTML-Seiten. Das sah dann – mit einem neu geschaffenen Navigationsframe – so aus:



Eine Suchfunktion gab es noch nicht. Man war vollständig auf die entsprechende Funktionalität seines Webbrowsers angewiesen. Mit zunehmendem Wachstum und fortschreitender Unterteilung der Cover-Versionen-Liste war es immer schwieriger, die richtige Liste zu finden, um darin zu suchen.
Am 5. März 2000 schließlich wurde die Sortierung auf eine solche nach Cover-Titeln umgestellt und jeder Anfangsbuchstabe (sowie die Ziffern 0-9 und der Rest) bekam eine eigene Liste. An diesem Tag kam aber auch endlich eine Suchfunktion, die alle gefundenen Einträge aus der Liste ausgab.
Mitte April 2000 wurde bereits die 2000. Cover-Version eingetragen. Es handelte sich um die Jetzendorfer Hinterhof-Musikanten mit "La Bamba", eine von ca. 40 weiteren zu jener Zeit in der Liste erfassten Versionen dieses Liedes. (Warum der Datensatz später neu erstellt wurde und heute mit dem Erstellungsdatum 7. März 2004 in der Datenbank steht, ist übrigens nicht überliefert.)

Seit Ende Mai 2001 war Thomas Wagner nicht mehr alleine mit der Pflege der Webseite beschäftigt. Herbert Zach gesellte sich dazu und ist der Redaktion bis heute als fleißiger Redakteur erhalten geblieben. Herbert hatte die Website am 28. Mai 1999 dank der Vorstellung in der Fernsehshow NBC GIGA kennengelernt und seither regelmäßig per E-Mail zum Datenbestand beigetragen.

Die neue Domain coverinfo.de
Am 9. Juni 2001 wurde erstmals kostenpflichtiger Webspace für den Betrieb der Website angemietet. Im Zuge dessen sollte die Website cover.here.de eine eigene Domain erhalten.Die Wunsch-Domain wäre cover.de gewesen, doch die war an eine Cover-Band namens COVER vergeben. Aus den Schlagzeilen war bekannt, dass es bald eine neue Top-Level-Domain geben würde: .info, die aber erst am 26. Juni 2001 starten sollte. Im Bewusstsein dieser Nachricht kam der Wunsch auf, die Domain cover.info zu bekommen, doch die konnte man am 9. Juni ja noch nicht bestellen. Aus diesem Grund wurde als Domain die Kombination coverinfo.de gewählt. Zwei Wochen später stieg coverinfo.de in den Betrieb des Diskussionsforums von Coverversion.de mit ein.




Die Seite hieß seitdem auch nicht mehr "Cover-Versionen in den Charts", denn von der ursprünglichen Auflistung von Songs, die es in die Charts geschafft haben, hatten wir uns längst entfernt.
Am 29. September 2001 begannen wir damit, Musikzitate (Samples und nachgespielte Elemente) von den Cover-Versionen in der Auflistung zu unterscheiden. Datensätze, bei denen es sich um vollwertige Cover-Versionen handelt, trugen fortan in der rechten Spalte ein "C" für Cover und die anderen ein "S" für Sample (ab 28. April 2003 stattdessen ein "Z" für den Oberbegriff "Zitat", der Samples einschließt).
Überforderte Technik
Ab 2002 kam coverinfo.de etwas heller und etwas weniger bunt daher. Im April 2002, 3 Jahre nach dem Start der Website, brachten wir es schon auf über 19.400 Einträge.Eine echte Datenbank war das Ganze zu dieser Zeit nach wie vor nicht, sondern eine Suche in HTML-Seiten, die alles andere als performant war, was irgendwann den Server in die Knie zwang.




Endlich eine echte Datenbank
Am 1. Juli 2002 war endlich Schluss damit, die Daten in einer großen Excel-Datei zu sammeln und mittels Virtual-Basic-Scripts in mehr oder weniger regelmäßigen Abständen in HTML-Dateien für den Webserver zu exportieren. Unsere MySQL-Datenbank ging an den Start. Dies verringerte die Antwortzeiten der Suchfunktion und Änderungen am Datenbestand gehen seitdem sofort live und nicht erst nach einigen Tagen.



Hinter den Kulissen arbeiteten wir mit Microsoft Access 2000, das über eine ODBC-Schnittstelle an die MySQL-Datenbank angebunden war. Für uns entwickelt wurden all die technischen Lösungen, die seit dem Jahr 2000 zum Einsatz gekommen waren, von ein paar fleißigen Nutzern der Website. Wir danken Achim Kaiser, Gerd Nachtsheim, Mike Wilhelm und Björn Hutzler. Ohne sie wäre coverinfo.de nie so weit gekommen, weshalb wir ihnen für ihre Arbeit danken.
Es wird professioneller
Am 1. September 2003 präsentierte sich die Website erstmals in einem professionell wirkenden Design, das uns von einem Nutzer der Seite, Marcel C., spendiert wurde.




Holger Kungs Werk
Doch am 4. Oktober 2007 erhielt die Website erstmals eine vollständig von der Redaktion, genauer gesagt von deren Mitglied Holger Kung, selbst entwickelte Relaunch. Die wesentlichen Designelemente der von Marcel C. entworfenen Seite blieben dabei erhalten.



Technisch wurde die Seite dabei komplett neu entwickelt. Damit ging eine Verbesserung der Datenbank-Suchfunktion einher, die nun intuitiver zu bedienen war als zuvor. Eine andere Neuerung war, dass zur deutlicheren Unterscheidung auf den ersten Blick in der Datenbank nun Cover fett angezeigt wurden und Musikzitate mager.
Für die Redaktion gab es erstmals ein Web-Interface, mit dem die Datenbank bearbeitet werden konnte, sodass keine plattformabhängige Zusatzsoftware mehr erforderlich war, sondern ein Browser genügte. Heutzutage ist so etwas fast selbstverständlich.
Nach 10 Jahren kontinuierlicher Arbeit hatten wir im April 2009 mehr als 181.000 Einträge gesammelt. Einen herben Schlag mussten wir am 23. April 2010 hinnehmen, als wir durch seine Freundin von Holger Kungs Tod erfuhren. Sein Werk – die Neuentwicklung der Website und der Datenbank aus dem Jahre 2007 und eine von ihm begonnene Liste von Interpreten mit Verwechslungsgefahr – lebte lange Jahre weiter. Seine Einträge, die er zur Datenbank beigesteuert hat, werden hoffentlich ewig Bestand haben.
Leider hat Holger keine ausführliche Dokumentation seiner Entwicklungsarbeit hinterlassen. Es erwies sich daher nicht als praktikabel, sein Werk fortzuführen. Allerdings stieß mit zunehmender Datenbankgröße die von ihm entwickelte Lösung auf Grenzen. Am 14. September 2010 verzeichneten wir 200.000 Einträge, am 5. November 2012 schon 250.000, am 16. Juni 2015 bereits 300.000, am 15. Juli 2017 beeindruckende 350.000 Einträge. Mit Workarounds konnten die Grenzen, die dem System gesetzt waren, noch eine Zeitlang verschoben werden, sodass es mit für den Nutzer kaum bemerkbaren Einschränkungen weiterlief. Gegen Ende des Jahres 2017 war es aber nicht mehr möglich, eine zuverlässig funktionierende Suchfunktion aufrechtzuerhalten. Immer häufiger bekamen Nutzer nur noch einen Teil der zu ihrer Suche passenden Datensätze zu sehen.
Das heutige COVER.INFO
Glücklicherweise war zu dieser Zeit unser Redakteur Falko Rickmeyer, der sich zwischenzeitlich zum Software-Entwickler ausbilden ließ, bereits dabei, die Website komplett neu zu entwickeln – zusammen mit Adrian Semmler, der das Design mit entworfen hat, und Thomas Wagner, unterstützt durch den Rest der Redaktion, der Gedanken zu einer Neustruktierung der Datenausgabe beisteuerte. Erstmals in der Geschichte der Website gab es keine Tabellendarstellung mehr mit Cover-Versionen links und Originalen rechts, sondern eine chronologische Darstellung, die es ermöglicht, Ketten abzubilden wie Cover-Versionen, die ein Original haben, das einen anderen Song sampelt, der wiederum einen anderen Song zitiert. Erstmals wird in diesem neuen Design auch Wert auf eine mobile Ansicht für die Nutzbarkeit auf Smartphones Wert gelegt.Am 6. Mai 2018 ging die neu gestaltete Website online, und zwar nun schlussendlich doch unter dem zwischenzeitlich käuflich erworbenen Domainnamen, von dem wir schon seit 2001 geträumt hatten, der aber damals schon früh vergeben war: COVER.INFO. Eine andere Domain als coverinfo.de war für das neue Konzept ohnehin notwendig, denn von nun an sollte die Seite international ausgerichtet werden und deshalb auch vollständig in englisch (neben deutsch) verfügbar gemacht werden, wozu eine regionale Domainendung nicht mehr passte.

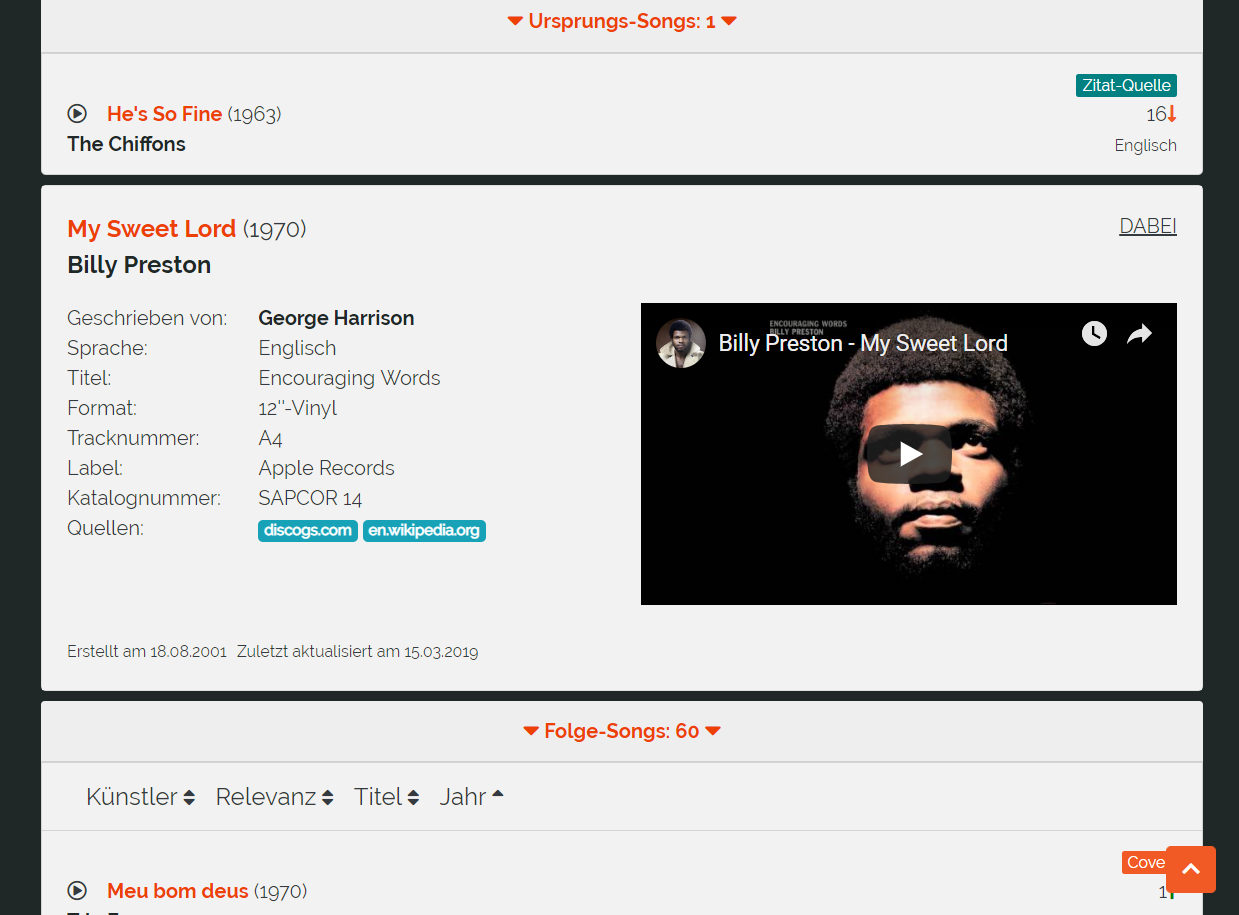
Die neue Darstellung hat einen Nachteil, weshalb es Beschwerden seitens der Nutzerschaft gab: Man konnte nun nicht mehr auf einen Blick in einer Übersicht sehen, welche Songs von welchen Künstlern ein bestimmter Interpret gecovert hat oder wer dessen Songs gecovert hat. Man musste jeden Song einzeln anklicken, um dies herauszufinden. Wir schufen Abhilfe mit der erweiteren Interpret-Ansicht, die am 19. Juli 2018 in Betrieb ging. Diese bietet nun auf Künstlerseiten unter dem Link "zur Tabellenansicht..." wieder eine tabellarische Darstellung aller Songs eines Interpreten – nun aber entsprechend dem neuen chronologischen Konzept andersherum als früher mit Originalen auf der linken und Cover-Versionen auf der rechten Seite.

Nach wie vor befindet sich COVER.INFO in der technischen Entwicklung, um den Funktionsumfang und die Nutzerfreundlichkeit sowohl für die Öffentlichkeit als auch für die Redaktion, die die Daten pflegt, zu erhöhen. Die Aufgabe, dies zu koordinieren, fällt seit 1. Juni 2018 dem gemeinnützigen Verein COVER.INFO n. e. V. zu, der die Verantwortung für die Pflege der Website von Thomas Wagner übernommen hat. So soll die Abhängigkeit der Website von einer Einzelperson minimiert und Zukunftssicherheit geschaffen werden. Zudem werden so steuerbegünstigte Spenden für den Erhalt der Website möglich.
Das Jubiläumsjahr bei COVER.INFO
Wir haben geplant, euch in den nächsten Monaten noch weitere Hintergrundinformationen über uns hier im Blog zu präsentieren.Doch jetzt seid ihr gefragt! An was aus der Geschichte von 20 Jahren COVER.INFO erinnert ihr euch noch? Seit wann kennt ihr uns? Schreibt es uns unter diesem Artikel in die Kommentare. Die Kommentarfunktion ist der Ersatz für das am 24. Mai 2018 abgeschaltete Diskussionsforum.
